
Characteristic | N = 6011 |
|---|---|
Age at therapy start | 40.25 (14.22) |
Sex | |
male | 227 (38%) |
female | 374 (62%) |
In relationship | 205 (57%) |
Unknown | 239 |
Marital status | |
single | 194 (54%) |
married | 98 (27%) |
divorced | 49 (14%) |
seperated | 12 (3.3%) |
widowed | 5 (1.4%) |
other | 4 (1.1%) |
Unknown | 239 |
General education | |
student | 6 (1.7%) |
no school-leaving certificate | 6 (1.7%) |
lower secondary school certificate | 59 (16%) |
intermediate secondary school certificate | 103 (28%) |
higher education entrance qualification | 184 (51%) |
other | 4 (1.1%) |
Unknown | 239 |
Vocational qualification | |
Currently in vocational training or studying | 43 (12%) |
No vocational qualification | 44 (12%) |
Apprenticeship / vocational training | 197 (54%) |
University or university of applied sciences degree | 56 (15%) |
Other | 22 (6.1%) |
Unknown | 239 |
Work ability status | |
Able to work | 202 (56%) |
Unable to work (on sick leave) | 110 (30%) |
Disability pension | 11 (3.0%) |
Old-age pension | 10 (2.8%) |
Other | 29 (8.0%) |
Unknown | 239 |
Previous psychotherapy | |
no prior treatment | 184 (37%) |
outpatient psychotherapy | 83 (17%) |
inpatient psychotherapy | 121 (24%) |
both | 101 (20%) |
exact specification not available | 14 (2.8%) |
Unknown | 98 |
CGI severity | |
Not assessable | 1 (0.2%) |
Normal, not at all ill | 0 (0%) |
Borderline mentally ill | 6 (1.2%) |
Mildly ill | 24 (4.8%) |
Moderately ill | 151 (30%) |
Markedly ill | 246 (49%) |
Severely ill | 74 (15%) |
Among the most extremely ill patients | 1 (0.2%) |
Unknown | 98 |
Primary depression diagnosis | 292 (49%) |
1Mean (SD); n (%) | |
If you want to suggest changes to the prose of the manuscript, please use the following Google Docs Link
TODO / Bounties
check whether categorization of depression_diagnosis is good, i.e., whether all depression diagnsois strings are caught by our method [Gabriel]
Test stats model assumptions visually
re-write abstract
Adapt results and discussion
Notes from our meeting:
Bring up the novel tests that we propose earlier
General claim should be that some validation procedures are regularly employed, but that this collection is incomplete, not that there is no validation
Integrate results from Oscar’s 2021 Harmony paper (already inserted in bibliography file)
Correlation between LBA scores across methods (scatter plot of CCR vs supLBA and see where predictions potentially depart)
Test incremental validity empirically?
Conceptual question about whether our framework is equally applicable to all common rating scales. A discussion was held about the case of wellbeing rating scales and LBAs. Is there the same expectation as to the causal relation between indicator and construct? Wellbeing is often expressed not directly, but instead behaviors are listed which lead to greater wellbeing (eg, spending time with friends). Also: How does our framework relate to formative as opposed to reflective measurement models?
Introduction
Rating scales are the predominating tool to measure psychological constructs. Psychological rating scales have been employed for decades and can be used in various contexts – from tightly controlled laboratory experiments to naturalistic research using ecological momentary assessment (Shiffman et al., 2008). What makes rating scales useful, in large part, is their face validity, ease of administration, and standardization. Yet, some of the shortcomings of rating scales, such as their susceptibility to biases and closed-ended nature, have motivated the development of alternative psychometric instruments (O. N. Kjell et al., 2019). That such tools are desirable is further emphasized by the fact that psychological researchers now frequently encounter study contexts where administering a rating scale might be unfeasible (e.g., big social media data) or strictly impossible (e.g., deceased individuals and historical records) (Atari et al., 2023; Chen et al., 2024; Plank & Zlomuzica, 2024b).
A growing body of work has demonstrated that analyses of natural language can yield rich insight into a person’s states or traits (O. N. Kjell et al., 2024; Plank & Zlomuzica, 2024a; Tausczik & Pennebaker, 2010). Language-based assessments (LBAs) aim to assess psychological constructs from natural language (Nilsson et al., 2026; Wright et al., 2026). While early approaches relied on word dictionaries, modern LBAs leverage transformer neural networks [i.e., Large Language Models (LLMs)] which are trained on vast amounts of language data and possess a rich contextualized language understanding (Devlin et al., 2019; Lake & Murphy, 2023; Vaswani et al., 2017). LBAs have been shown to enable accurate predictions of participants’ scores on mental health rating scales assessing depression (Gu et al., 2025; J.-J. Lee et al., 2026), anxiety (Gu et al., 2025; Stade et al., 2023), post-traumatic stress (O. Kjell et al., 2026), as well as positive mental health dimensions such as harmony (O. Kjell et al., 2021) and well-being (O. N. Kjell et al., 2022). The performance of LBAs now frequently approaches measurement-theoretic ceilings established by the internal- and test-retest reliability of rating scales questionnaires [a measure of ground-truth noise(O. N. Kjell et al., 2022, 2024)].
Despite their ability to generate highly accurate predictions of self-reported constructs and their potential for streamlining and scaling psychological assessment, there has been a paradoxical lack of clinical deployment of LBAs (Cohen, 2019). A major reason for this lack of translation is the fact that most LBAs remain rather crudely, if at all, evaluated on psychometric grounds (Cohen, 2019; Cohen et al., 2022). In technical fields such as computer science, assessments are appraised mainly in terms of precision or accuracy which are broadly analogous to the concepts of reliability and validity in classical test theory (Cohen, 2019). Yet even in psychological science, LBAs are frequently deployed under the implicit assumption that they provide valid construct assessments without formal proof or validated narrowly in terms of convergent validity – that is, convergence of language-assessed scores with self-report scores (Bilgrami et al., 2022; Dohnány et al., 2026; Eberhardt et al., 2025). The use of insufficiently validated measurement instruments raises major concerns to both research and clinical settings. In clinical settings, where LBAs are hoped to soon guide clinical decision making (Hüppi et al., 2025), improper validation undermines the trustworthiness of LBAs and risks false diagnoses and erroneous treatment choices (Plank & Zlomuzica, 2025). In research, it risks false conclusion about what construct was measured and raises doubt about research findings that are generated downstream of such measurement (Flake et al., 2017). To establish LBAs as mainstay tools and move beyond perpetual proof of concept studies, it is vital that they are held to the strict standards of psychological test theory (Cohen, 2019; Cohen et al., 2022; O. N. Kjell et al., 2024). Promisingly, recent works have seen a shift towards more comprehensive psychometric evaluations of LBA that extend beyond convergent validity, probing such phenomena as divergent and criterion validity (Cohen et al., 2022; O. N. E. Kjell et al., 2019; Wright et al., 2026).
There is increasing recognition of the importance of evaluative frameworks for AI-based assessments in psychiatry more generally (Chandler et al., 2020). Yet, to our knowledge, no dedicated framework has thus far been defined for LBA. Since LBAs are treated as though they are psychological tests, we contend that their evaluation should also be grounded in psychological test theory. The present article submits just such a framework for the validation of LBA. When LBAs are cast in terms of psychometric theory, it is revealed that their reliance on language as a behavioral readout positions them as a unique case which requires validation procedures not seen in traditional rating scale validation. This necessitates an extension of classical validation procedures which is provided here in the form of a set of tests targeting domain generalization, interpretability, and ecological validity of LBAs.
The article is structured as follows: Readers are first briefly introduced to neural text embedding methods which lay the technical groundwork for LBA. Afterwards, two predominating contemporary approaches to LBA are presented and formalized in terms of psychometric theory. Finally, a novel evaluation framework, composed of a set of empirical and substantive tests of validity, is presented and illustratively applied to LBA of depression symptoms.
Semantic embedding models
Contemporary LBA relies on a class of methods originating from natural language processing research known as semantic embedding models. We here provide only a brief functional and technical introduction to these models and refer readers elsewhere for more detailed expositions (Lake & Murphy, 2023).
Semantic embedding models allow quantifying the semantics, i.e. content or meaning, of texts (Lake & Murphy, 2023). To this end, pieces of texts, such as words, sentences, or paragraphs, are transformed into high-dimensional vectors known as embeddings (Mikolov et al., 2013). Having embedded multiple pieces of texts into semantic space, one may compute the distance between them which indicates their semantic similarity (Lake & Murphy, 2023). For example, the two words “sad” and “unhappy” will reside closer in semantic space than the words “sad” and “happy”. Because embeddings are high-dimensional, distance is assessed not based on Euclidean but angular metrics, namely the cosine similarity (Lake & Murphy, 2023). Cosine similarity measures the angular alignment of two embeddings. A perfect alignment with a cosine similarity of 1 indicates two semantically identical texts. An opposite alignment with a cosine similarity of -1 indicates two maximally dissimilar texts. There are two central properties of semantic embeddings that are important to note here and which will be returned to later: For one, semantic information is distributed over the entire vector rather than locally contained in any individual dimension (Piantadosi et al., 2024). Embeddings are also relational in the sense that their isolated position is meaningless but their position relative to other embeddings carries semantic information (Piantadosi et al., 2024).
There are various types of semantic embedding models, but all models follow the general notion of distributional semantics – words that co-occur or that occur in similar contexts have shared meaning (Firth, 1957; Harris, 1954; Lake & Murphy, 2023). Thus, to generate models which can represent the semantics of texts, word co-occurrence patterns across large language corpora are analyzed (Mikolov et al., 2013). Modern embedding models (and modern LBAs) rely on artificial neural networks and will be the focus in this article (Lake & Murphy, 2023). While there are implementational differences, a common feature is that they are trained to predict missing words based on their context and adapt their internal representation (i.e. the mapping from words to embeddings) according to their ability to do so (Devlin et al., 2019; Mikolov et al., 2013). While early embedding models were rather context-free and only able to provide embeddings of isolated words, more recent models can generate contextualized embeddings that consider the context within which a word was used (Devlin et al., 2019). To do this, they use a specific neural network architecture known as the transformer (Vaswani et al., 2017). The two defining features of transformers is their ability to model word order (“I am hungry” != “Am I hungry”) and token dependencies (Vaswani et al., 2017). The latter causes word vectors to adapt to their surrounding contexts such that, for example, polysemic words like “bank” are adapted to encode different meanings based on context (e.g., finance vs. rivers) (Lake & Murphy, 2023). These features allow transformers to generate semantic embeddings for sentences and paragraphs whose meaning is compositional (i.e., more than the sum of the meaning of their constituent words) (Lake & Murphy, 2023). Resulting models generate semantic embeddings that perform extraordinarily well on a wide variety of text-based tasks (Devlin et al., 2019).
Contemporary approaches to LBA
The standard approach to LBA relies on semantic embedding models and supervised learning and will hereafter be referred to as supervised LBA. Supervised LBAs learn to predict scores on self-report scales based on language samples in a data-driven fashion. To this end, a collection of language-rating pairs is collected from participants. Language samples are then embedded (typically using transformers) and input as predictors into multiple linear regression models with rating scale scores as the criterion (O. N. Kjell et al., 2022, 2024; Teitelbaum & Simchon, 2025). The ability of supervised LBA models to predict rating scales can be assessed by measuring the overlap between language-predicted scores and self-reported scores (O. N. Kjell et al., 2022; Teitelbaum & Simchon, 2025). To avoid overfitting and gather unbiased estimates of performance, performance is measured on language-rating pairs not seen during training.
Recently, a theory-driven approach to LBA has been proposed that does not require training on data in a supervised learning sense. Contextualized Construct Representation (CCR) probes how closely a participant’s language aligns with the items of a rating scale (Atari et al., 2023; Teitelbaum & Simchon, 2025). For example, an individual with high depressive symptoms might produce language that more closely reflects items of depression rating scale such as “I am so sad and unhappy that I can’t stand it” (Beck et al., 1996). To this end, items of validated rating scales are embedded into semantic space. The CCR is then defined as the average (centroid) of item embeddings and the semantic similarity of a text to the CCR indicates how much the construct is present in the text (Atari et al., 2023). As Teitelbaum & Simchon (2025) note, CCRs possibly reflect not only the target construct, but also the style in which rating scale items are formulated (“Questionnaire-ness”) and propose anchored CCR to address this issue. To generate anchored CCRs, averaged embeddings of negatively formulated items (i.e., items that reflect construct absence) are subtracted from the averaged embeddings of positively formulated items (i.e., items that reflect construct presence) (Grand et al., 2022; Teitelbaum & Simchon, 2025). In theory, this “partials out” the questionnaire-ness of items and leaves only the construct relevant language to define the vector representation (Teitelbaum & Simchon, 2025). Current evidence suggests that CCR can enable LBAs which correlate with rating scales for the constructs of perceived locus of control and moral concerns (Atari et al., 2023; Teitelbaum & Simchon, 2025).
Measurement versus prediction
Cronbach (1949) defined psychological tests as systematic procedures for comparing the behavior of two or more people (Furr, 2021). While the behavior in question in modern psychology is most often a participant’s response on a rating scale, this classical definition allows for other types of behavior (such as language) to constitute psychological measurement. When LBAs are considered as psychological tests, their evaluation should be grounded in psychometric test theory. Validity is the most fundamental and important property of a psychological test and concerns whether the test measures what it intends to measure (Grimm & Widaman, 2012). More formally, a test may be considered valid when A) the target construct exists and B) variation in the construct is causal to variation in the test’s items (Borsboom et al., 2004). In reflective measurement models, observable variations in behavior (e.g., rating scale item responses) are caused by or reflective of variation in the latent construct (e.g., depression) (Borsboom et al., 2004).
Borsboom et al. (2004) emphasizes that the causal relation between indicator and construct is most central to the validity definition. Moreover, he differentiates between substantive validation, which largely takes place at the level of test construction when indicators are selected that are believed to reflect the construct, and empirical validation, which provides circumstantial evidence of validity through convergent, divergent and criterion-oriented analyses. For rating scales, substantive validation is straightforward because items are interpretable verbal descriptions. We may reasonably assume that depression causes changes in how much a person agrees with the statement “I am so sad and unhappy that I can’t stand it” (Beck et al., 1996). For both predominating approaches to LBA, however, the path to establishing validity is considerably less straightforward, and current validation practices leave important gaps.
In supervised LBA, indicators are semantic embedding dimensions which, as discussed earlier, carry no isolated meaning (Piantadosi et al., 2024). The indicator-construct-relationship is not defined a priori but learned through supervised methods. It may thus be characterized as a stable statistical association without merit for a causal claim. The theory-driven construction stage that Borsboom et al. (2004) identifies as a major source of validity is therefore largely absent. Substantive validation can be approximately probed via word cloud visualization, where words are plotted based on whether they tend to occur in texts with high or low language-assessed construct measurement (O. Kjell et al., 2023). While this method is one of the useful ways for which a model’s internal workings can be inspected and validated, it is limited as models are expected to learn semantic patterns that extend beyond individual words. In fact, the choice of using transformers is explicitly grounded in this notion. Because models do not generate predictions from isolated words and inspecting model predictions only at that resolution will often be insufficient. Some relevant patterns that emerge only in composition (such as grammatical errors which could be indicative of educational attainment) are entirely lost in this approach. The responsibility of establishing validity is then almost entirely placed on empirical validation procedures which can show that LBAs exhibit convergent, divergent, or criterion validity (Cohen et al., 2022; O. N. Kjell et al., 2024; O. N. E. Kjell et al., 2019). The sum of results of these validation procedures is taken as evidence of the test’s total level of construct validity, which is typically conceived as a matter of degree – tests are considered more or less valid dependent on the total sum of the evidence derived from a variety of validation procedures (Grimm & Widaman, 2012). The fact that LBAs overwhelmingly tend to conform to tests of convergent, divergent, and criterion validity has led to the conclusion that they are valid measurement tools (O. N. Kjell et al., 2024; Wright et al., 2026). Yet here a deeper issue arises.
In critique of validation procedures that attempt to maximize criterion validity, Borsboom et al. (2004) notes that choosing indicators based on their ability to predict a criterion will lead to lower construct validity, because highly correlated indicators (which reflect a singular coherent construct) tend to be multicollinear, therefore effecting subpar predictive performance. Supervised LBAs combine informationally dense semantic representations with data-driven methods that operate on the singular objective of optimizing predictive accuracy. A well-performing model therefore leverages not only semantic patterns reflective of the target construct but exhausts all information that is predictive of it. Consider, for example, a supervised LBA trained to predict self-reported depression symptoms. There will exist many tertiary variables that are both related to depression and simultaneously known to be reflected in language use (e.g., age, gender, income, educational attainment) (Giorgi et al., 2022; Sap et al., 2014). It is therefore entirely possible for a supervised LBA model to satisfy to empirical tests of convergent, divergent, and criterion validity as well as substantive tests of word cloud visualization, while its measurement of the target construct is systematically confounded by the simultaneous, unintended measurement of other constructs. An analogy can be drawn to a depression rating scale which includes participants’ gender as an item because this improves the prediction of depression diagnoses [which have a higher prevalence in women (Nolen-Hoeksema, 2001)]. Detecting such confounding lies beyond the reach of the standard validation procedures.
CCR addresses several of these concerns but introduces others that are equally invisible to conventional validation methods. Because CCRs derive measurement from semantic similarities between participant language and theoretically grounded scale items, the indicator-construct relationship is specified a priori and may plausibly be regarded as causal. Also, much of its content validity is inherited from ratings scales that have been validated over decades (Atari et al., 2023) which substantiates the claim that chosen verbal descriptions reflect the target construct as opposed to merely predicting it. Yet this apparent advantage comes with its own unexamined risks. The construct representation might be confounded by the academic linguistic register in which rating scale items are formulated (Teitelbaum & Simchon, 2025). Furhtermore, the stereotypical phrasing of scale rating items might poorly represent how constructs are expressed in naturalistic setting, causing CCR to miss domain-specific expressions such as neologisms and euphemisms in online language (e.g., “sewer slide” as a euphemism for “suicide” to bypass automated content filters on social media platforms) (Steen et al., 2023). Finally, while CCR operates on interpretable and seemingly unconfounded semantic similarity computations, the embedding space itself may be biased. That biases and stereotypes are inherent to semantic embedding models is well-established (Bolukbasi et al., 2016). Training on vast uncurated corpora causes models to learn the inherent biases of human language use, which could yield, for example, systematically higher similarity to depression statement for texts disclosing female gender. Crucially, none of these issues would be detected by standard convergent, divergent, or criterion validity analyses, because such analyses only assess whether CCR scores covary with rating scales and external criteria, not whether the similarity computation itself is biased or confounded.
In sum, supervised LBA and CCR face distinct but equally consequential threats to their construct validity, that are not detectable by the convergent, divergent, and criterion validity analyses which currently constitute the primary and often the sole procedure of LBA validation. This motivates the development of an extended evaluation framework which complements these standard procedures with tests specifically designed to surface such threats. The framework proposed below provides just such a set of procedures.
A psychometric evaluation framework
The following framework proposes a set of validation procedures. We note that no singular procedure, nor the entire set is to be viewed as conclusive evidence of construct validity. Substantive and empirical procedures are further understood as complimentary. In Table 1, all procedures are summarized.
Convergent, Divergent, and Criterion Validity
To test convergent validity, measurements derived from LBA are related to other measures of the same construct. The best fitting candidate measure to establish construct validity is dependent on the target construct but for many psychological constructs will be scores on a self-report rating scale. To establish divergent validity, correlations with the self-report measures of the target construct can be contrasted with self-report measures of a different but related construct. Finally, criterion validity can be established by examining whether LBA scores correlate in expected ways with a network of criteria that have previously been validated. For example, LBA scores of depression may be related to the clinical diagnosis of a depressive disorder or the number of visits to mental healthcare clinics (Gu et al., 2025; Grimm & Widamann, 2012).
Content Validity
Content validity concerns whether a psychological test covers the entire spectrum of the construct to be assessed (Grimm & Widaman, 2012). Content validity is appraised using substantive methods, namely expert evaluations (Grimm & Widaman, 2012). A collection of procedures with varying levels of formalization can be used to evaluate the content validity of LBAs.
First, a large portion of the degree of content validity is determined a priori at test construction (Borsboom et al., 2004). The content validity of CCR is thus to some extent inherited from the rating scale it is based on. Having chosen, and possibly slightly reformulated or negated items, a next step is to determine whether item content also represents a coherent construct to the semantic embedding model. To formalize this, we can compare the semantic similarity of items among the scale [e.g., Beck’s Depression Inventory (Beck et al., 1996)] to the similarity of items of the target scale to items of different but related scales (anxiety or stress inventories) (Grand et al., 2022). Furthermore, we may probe whether items of the target scale are more related to items of another scale measuring the same construct [e.g., Patient Health Questionnaire (Kroenke et al., 2001)] than to items of different but related scales. While the above procedures are applicable only to CCR, there are some procedures that also apply to supervised LBA. To inspect whether the test carries information of the entire spectrum of the construct, experts may manually annotate texts based on whether they carry information about the construct or subdomain thereof. These annotations may then be classified based on the text’s LBA scores. If statistically significant classification is consistently possible, the target domain, and all investigated facets are captured by the test. Other approaches include word cloud visualization (O. Kjell et al., 2023) and manual inspection of corresponding pairs of LBA scores and texts.
Representational Interpretability
The lack of interpretability of LLMs is often discussed as undermining their trustworthiness (Hüppi et al., 2025). A central reason is their black box nature whereby the internal representation of LLMs is not necessarily interpretable to Humans. There are ample efforts in the field of computer science known as mechanistic interpretability to find methods which improve our understanding of the complex mechanisms underlying LLMs (Sharkey et al., 2025). Improving interpretability in the application of AI in psychiatry has generally proven quite difficult with some authors concluding that “While we believe in striving toward explainability, a more realistic goal is transparency and generalizability.” (Chandler et al., 2020). We find that semantic embedding models provide a promising opportunity for more detailed inquiries into how constructs are learned to be represented internally.
The proposed validation procedure involves comparing the learned internal representation of the target construct in supervised LBAs with the theory-defined construct representation as defined via CCR. If a model has learned to represent the target construct, its internal representation should be similar to the CCR. The representational similarity can be determined by computing the cosine similarity between CCR and the set of coefficients stored in the fitted regression model. Importantly, CCR serves here not as a validated gold standard but as a theory-derived expectation, i.e. what the model should have learned if it has captured the target construct as operationalized by the underlying rating scale. Analyses presented later in this article demonstrate that the use of partial least square regression and anchored CCR might be particularly suitable for this analysis.
Domain Generalization
Domain generalization concerns the ability of models to solve tasks in evaluation domains that differ from the training domain and is a classical problem in natural language processing research (Hupkes et al., 2023; Pan & Yang, 2009). Domain generalization indicates whether models have truly learned to solve a task or instead have learned simple heuristics which serve as effective solutions only in the training domain (Hupkes et al., 2023). The rationale for probing the domain generalization of supervised LBA is similar; if a supervised model has converged on a representation of the target construct itself, its performance should be largely invariant to the domain in which construct-relevant language is produced, because the construct (not the domain) is the common cause of the relevant linguistic variation. If, by contrast, a model rests in part on domain-specific correlates – for example, an LBA model trained on social media texts that picks up features associated with, but not reflective of, depressive symptoms – performance should deteriorate when the model is deployed in domains where these correlates are absent or differently distributed. Importantly, if confounding correlates are present in all tested domains and are also similarly distributed, non-valid models would also generalize well. Domain generalization is therefore a necessary but insufficient criterion of validity and should hence be only one of many validation procedures.
There will often not be any prior knowledge as to whether the construct is expressed in the investigated domain. A practical solution to this issue is to first establish a benchmark by correlating CCR-derived scores with rating scale scores. Successful domain generalization can then be asserted if text-rating correlations fall around this benchmark. The importance of deploying trained LBAs across novel domains is increasingly being recognized (Nilsson et al., 2026), although empirical evidence for or against their ability to generalize is markedly lacking. Indeed, some have voiced doubts about models’ ability to generalize to data-sets that diverge too strongly from the training domain (Nilsson et al., 2026; Teitelbaum & Simchon, 2025). One way to test generalization is to test LBA models trained in one research site on data accrued in another. The re-use of LBA models is facilitated by the LBAM package in R which stores fitted LBA models and enables simple deployment on novel data (Nilsson et al., 2026).
Ecological Validity
The development of LBAs often takes place in settings where participants are guided to produce language that will more strongly reflect their score on the target construct. During clinical interviews, participants are guided to talk about their mental health symptoms (First, 2014). Experimental methods sometimes provide even stronger guidance as to the content that participants should produce. Gu et al. (2025) designed a language elicitation method where participants were asked to describe their depression and worry symptoms which yielded strong text-rating correlations. While such settings are important for the development and validation of LBAs, they are relatively artificial and possibly do not reflect language use in naturalistic environments. Thus, it is vital to prove that LBAs measure a behavior which naturally occurs. An arguably highly naturalistic setting can be found in social media language which is produced spontaneously and collected retrospectively (Plank & Zlomuzica, 2025), thus circumventing behavioral modulation due to study participation [e.g., Hawthorne effect (Adair, 1984)].
| Validation Procedure | Core Question | Statistical Operationalization |
| Convergent Validity | LBAs converge with other measures of the target construct (e.g., rating scales) | \(r\)(LBA, Rating) > 0, \(p\) < .05 |
| Divergent Validity | LBAs converge less with measures of different but related constructs | \(r\)(LBAtarget, Ratingnon-target) < \(r\)(LBAtarget, Ratingtarget), \(p\) < .05 |
| Criterion Validity | LBAs are related to external criteria known to be associated with the target construct | Concurrent, Predictive, Postdictive: \(r\)(LBA, Criterion) > 0, \(p\) < .05 Incremental: \(R^2\)(LBA + Rating, Criterion) > \(R^2\)(LBA, Criterion), \(p\) < .05 |
| Content Validity | LBAs cover the entire spectrum of the target construct | CCR:
sLBA + CCR:
|
| Ecological Validity | The target construct is naturally expressed in language | \(r\)(LBA, Rating) > 0, \(p\) < .05, in spontaneously produced language (e.g., social media) |
| Domain Generalization | LBAs generalize across different settings | \(r\)(sLBADomain A, RatingDomain B) ≈ \(r\)(CCR, RatingDomain B) |
| Representational Interpretability | Overlap of learned and theory-defined construct representations | \(\cos\)(sLBARepresentation, CCRRepresentation) |
Note. \(r\) = correlation, \(\cos\) = cosine similarity, CCR = Contextualized Construct Representation, LBA = language-based assessment (either CCR or supervised LBA), sLBA = supervised LBA, Rating = scores on self-report rating scale.
Methods
This manuscript and all accompanying analyses are generated from a Quarto notebook (Allaire et al., 2022)1. The notebook and all data required to replicate analyses is provided in a Github repository2. Readers are encouraged to inspect coded behind analyses and reproduce analyses following different analytical choices. Pre-processing and NLP analysis were conducted mostly in Python (Van Rossum & Drake Jr, 1995) and statistical analysis were conducted in R (Team et al., 2016).
Ethics
All procedures presented in this study are in accordance with the Declaration of Helsinki. Next to re-analyses of existing data-sets, we present a novel data-set of mental health anamnesis texts. All procedures concerning the collection and analysis of this data were approved by the university’s local ethics committee (approvals #318 and #431).
Datasets
META-FBZ
META-FBZ comprises data (N = 601) that was routinely gathered at a university outpatient mental health center in Germany between 2017 and 2024. The data-set includes socio-demographic variables (age, sex, education, vocational qualification, and current work ability), mental health diagnoses according to the DSM-5 (ascertained by a clinical psychologist through a semi-structured clinical interview), psychometric questionnaires [Beck-Depression-Inventory-II (Beck et al., 1996; Kühner et al., 2007), Depression Anxiety Stress Scale 21-item version (Lovibond & Lovibond, 1995);Nilges & Essau (2015)]], and open-ended patient narratives designed to assess key aspects of their mental health concerns, functional impairments, and expectations for treatment. Responses to the following seven questions were analyzed in this study:
Problem development: “Briefly describe how the problems for which you are seeking treatment have developed over time.”
Extra stressors: “What causes you stress in addition to your everyday problems (e.g., finances, housing situation)?”
Pre-onset changes: “Did something special change in your life before the onset of your symptoms? (e.g., death of an important person, divorce or separation, change in work situation or income, addition to the family)”
Event connection: “Do you see a connection between the event(s) and the development of your problems?”
Physical symptoms: “Are there any physical side effects when your problems occur?”
Problem description: “Finally, please describe in your own words the problems for which you would like treatment.”
Impacted life areas: “In which areas of your life do these problems limit you (e.g., job, relationship)?”
Open-ended responses which were available only in paper-pencil format were voice recorded and transcribed using a local instantiation of the speech recognition model whisper-large-v23. To anonymize texts , personal information such as names of persons, places, or organizations were substituted with placeholders using named-entity-recognition4 implemented in the flair library. We included only responses with at least five words and appended all text responses to yield a singular text per patient. Sociodemographic and clinical characteristics of the sample are reported in Table 1.
dep_wor_data
dep_wor_data is a publicly available data-set5 containing data from 500 participants recruited from Prolific (Palan & Schitter, 2018). It includes sociodemographic variables (age, gender), psychometric questionnaire scores measuring depression [PHQ-9, (Kroenke et al., 2001)] and generalized anxiety [GAD-7, (Spitzer et al., 2006)], information on the number mental health-related sick leaves and healthcare visits in the past year, and open-ended text responses. Open-ended text instructions asked participants to describe their depression or worry symptoms in their own words. Different formats were used, asking participants to describe their symptoms using words/phrases or paragraphs. For this study, we used paragraph descriptions [for more information, see (Gu et al., 2025)]. In this study, only texts containing at least five words were included. For some analyses (see Section 3.2.5.1) it was necessary for depression scores to have a common scales. Consequently, PHQ-9 scores were transformed into BDI-II scores using established methods (Wahl et al., 2014).
eRisk
eRisk is an annual competition aiming to foster the development of early mental disorder detection through computational methods. Two datasets from past eRisk competitions which are available to qualified researchers6 were used in this study. In Task 3 of the 2021 competition involved predicting self-reported depression symptoms (BDI-II) from the social media posts of 80 Reddit users (Parapar et al., 2021). In the present study, post titles and bodies were appended to yield singular texts and only texts with at least five words were included. Task 1 of the 2025 competition contains 11,042 sentences extracted from Reddit posts that were manually scored as being relevant (= 1) or irrelevant (= 0) to BDI-II items (Crestani et al., 2022; Parapar et al., 2025). Relevance was defined as sentences which indicate symptom presence, irrespective of whether they are positive (i.e., user describes having symptom) or negative symptom description (i.e., user describes not having symptom). Rating was conducted by two computer scientists and one psychologist and final ratings were defined by consensus (Parapar et al., 2025). In both eRisk datasets, texts were cleaned of Reddit-specific markdown using the redditcleaner package.
Contextualized Construct Representation
The process of creating a CCR for the depression construct is illustrated in Figure 1. First, items of the Beck-Depression-Inventory-II (BDI-II (Beck et al., 1996)), one of the most commonly used depression self-report questionnaires, are transformed into vectors using a semantic embedding model. The CCR is then defined as the average (or centroid) of all 21 individual item vectors (\(\mu_{pos}\))(Atari et al., 2023). To measure CCR loadings (i.e., how much the depression construct is present in a given text), we determine the similarity between the text’s vector and the CCR (Atari et al., 2023). Since semantic embedding models operate in high-dimensional space, similarity between two vectors is assessed using cosine similarity which ranges from -1 (low) to 1 (high), and quantifies whether the two vectors have a similar orientation (Lake & Murphy, 2023).
Following suggestions of Teitelbaum & Simchon (2025), the use of anchored CCR (aCCR) was explored. While standard CCRs are defined as the centroid of positively formulated items (\(\mu_{pos}\)), aCCRs are instead defined as the difference of centroids of positively and negatively formulated items (\(\mu_{pos}\) - $\mu_{neg}$). As noted by Teitelbaum & Simchon (2025), anchoring CCRs could address the fact that questionnaire items reflect not only the target construct but also a specific (academic) writing style [c.f. questionnaire-ness (Teitelbaum & Simchon, 2025)]. We used formulations in the English (Beck et al., 1996) and German (Kühner et al., 2007) versions of the BDI-II to define CCRs and aCCRs. The BDI-II is useful for this purpose as it provides descriptions for both the absence and presence of symptoms. For two symptoms, namely sleep and appetite, there are two opposite descriptions indicating symptom presence (increase and decrease in appetite/sleep duration). We reformulated these to “I have experienced changes in my [appetite/sleeping pattern]”, respectively.
We used an open-source bilingual (English/German) sentence embedding model with 560M parameters7 (S. Lee et al., 2024). The model is optimized for German information retrieval and achieves state-of-the-art performance on MTEB benchmarks. It was trained via fine-tuning a base model on 30M pairs of high-quality German texts. The base model was another multilingual sentence embedding model with 24 layers and 1024 embedding dimensions that was trained on diverse text data including Wikipedia, News, Reddit, academic articles, etc.8 (Wang et al., 2024).
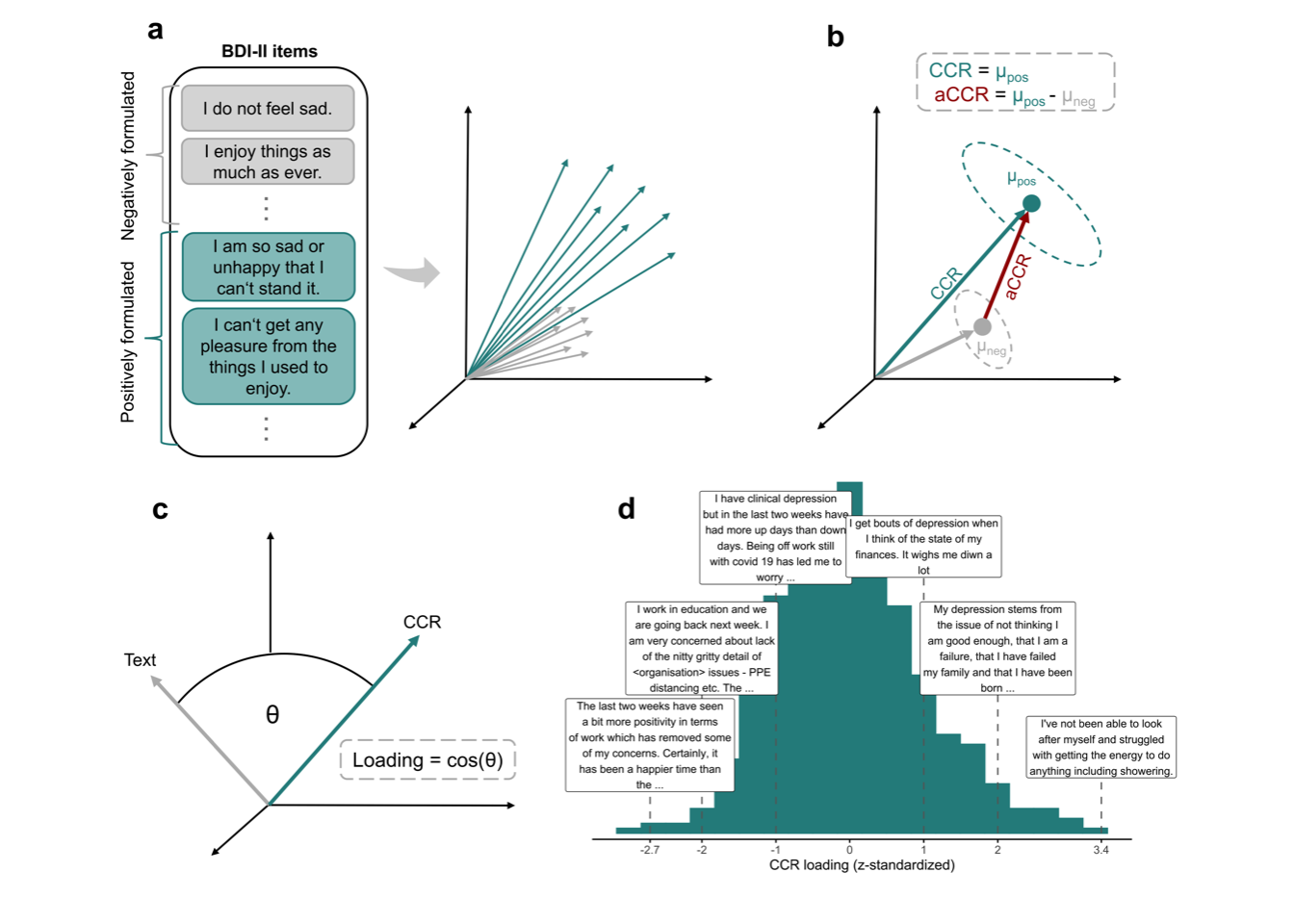
Note. a, Items of the BDI-II are transformed into semantic vectors. b, the CCR is derived by computing the average (centroid) of positively formulated BDI-II items (blue vector). The anchored CCR (red vector) is instead defined as the vector connecting the centroid of negatively formulated items with the centroid of positively formulated items (grey vector). Mathematically this vector is derived by subtracting the latter from the former. c, CCR/aCCR loading indicates how closely the depression construct is present within a given text. CCR/aCCR loading is computed as the cosine similarity of the CCR/aCCR vector with a given text vector. Perfect alignment of vectors (cosine similarity = 1) indicates high loading, while opposite alignment (cosine similarity = -1) indicates low loading. d, CCR/aCCR loadings for example texts taken from depression texts in the dep_wor_data dataset.
Statistical Analysis Plan
Significance was asserted at p < .05 and assumptions of statistical models were checked via residual histograms, QQ-plots, and fitted-residual plots.
Supervised LBA
The performance of CCRs was compared to supervised LBA. To this end, sentence embedding vectors were used to train regression models to predict self-report scales. Two different regression models were used. Ridge Regression (RR), the standard model for supervised LBA (Gu et al., 2025; O. Kjell et al., 2026; Teitelbaum & Simchon, 2025), shrinks regression coefficients by penalizing maximum likelihood parameter estimates to address over-fitting. The degree of penalization can be tuned using the \(\alpha\) parameter where high \(\alpha\) values correspond to strong penalization. Partial Least Square regression (PLS) was submitted by Teitelbaum & Simchon (2025) as another method for supervised LBA (c.f. Correlational Anchored Vectors). PLS extracts from the predictors a set of orthogonal factors which have the highest predictive power (Abdi, 2003). PLS is thus useful when in cases with a large number of correlated predictors (Abdi, 2003). By extracting only a singular factor with the highest predictive power, the model could learn a more abstract construct representation which might lead to enhanced generalization performance on comparable text samples (Teitelbaum & Simchon, 2025).
To evaluate the performance of supervised LBA, 5-fold cross validation was conducted. For RR, cross-validation was nested to allow for a hyper-parameter search for optimal \(\alpha\) in 100-step log-space from 101 to 106. Embeddings were z-standardized on each fold individually. Predicted questionnaire score on the training data-set were extracted from outer fold predictions. Best fitting models were used in transfer tests to predict questionnaire scores in other data-sets. High text-rating correlations on data-sets not seen during supervised learning indicates good generalization performance.
Content Validity
A content analysis of individual items was conducted to test whether CCRs represent a coherent construct that is distinct from other related psychopathology constructs, namely anxiety and stress. A similar procedure to Grand et al. (2022) was followed; positive items of the BDI-II embedded and compared to the embeddings of the Depression-Anxiety-Stress-Scale (42-item version) (Lovibond & Lovibond, 1995). The semantic similarity among BDI-II items (i.e., within similarity) was compared to the semantic similarity of BDI-II items to DASS-42 anxiety and stress sub-scale items (i.e., between similarity) via a Welch t-test. An increased within vs. between similarity was hypothesized. Additionally, the similarity of BDI-II items to the DASS-42 depression sub-scale was compared to the similarity of BDI-II items to the Anxiety and Stress sub-scale via pairwise Welch t-tests. Similarity to Depression items was expected to be elevated when compared to both anxiety and stress items.
A psychometric tool can be considerd to have high content validity if it represents the entire spectrum of the construct (or syndrome) to be assessed. To test this, the semantic similarity of Reddit sentences to the positive (\(\mu_{pos}\)) and negative (\(\mu_{neg}\)) BDI-II centroids were used to predict manual symptom relevance ratings (0 = irrelevant, 1 = relevant) for all 21 BDI-II symptoms individually. A logistic regression was used and performance was assessed via the area-under-the-receiver-operating-curve (AUROC). Significance was determined by checking whether the CI of the AUROC includes 0.5 (chance-level).
Convergent Validity
Pearson correlations were used to test for significant associations between language-assessed depressivity and self-reported depressive symptoms. To compare the magnitude of text-rating correlations for different LBA methods, Steiger tests were conducted (Steiger, 1980).
Divergent Validity
Pearson correlations were used to test whether language-assessed depressivity would correlate with other mental health symptoms. Correlations of LBAs with depression scores (DASS-21-Depression in META-FBZ; PHQ-9 in dep_wor_data) were compared with correlations of LBAs with anxiety (DASS-21-Anxiety in META-FBZ; GAD-7 in dep_wor_data) and stress self-reports (DASS-21-Stress in META-FBZ). Steiger tests were conducted to statistically compare correlations.
Criterion Validity
Associations of language-assessed depression with four external criteria served as tests of criterion validity. In META-FBZ, primary diagnosis of a depressive disorder (semi-structured clinical interview) and work ability status (currently working vs. on sick leave) served as external criteria. Comparisons were made using Welch t-tests. In dep_wor_data, the number of healthcare visits and sick leave days in the past year served as external criteria. Pearson correlations were used to test for these associations.
Results
Descriptive Statistics
Table 2 shows descriptive statistics of the three data-sets, totalling N=1181 participants. In samples with available demographic information, the mean age was between 33.62 and 42.5 years and between 39.4 and 62.2% of participants were female. Based on common cut-offs, between 17.4 to 42.5% of participants were severely depressed. In the data-set with the fewest number of words per person, participants provided responses that were on average 55 words long, indicating sufficient data for language analyses.
| dep_wor_data | eRisk-2021 | META-FBZ | |
|---|---|---|---|
| Sample | |||
| N | 500 | 80 | 601 |
| % Female | 39.4 | — | 62.2 |
| Age, M (SD) | 33.62 (11.87) | — | 40.25 (14.22) |
| Depression | |||
| Measure | PHQ-9 | BDI-II | BDI-II |
| Score, M (SD) | 11.49 (7.53) | 28.4 (12.65) | 23.47 (12.73) |
| % Severe depression | 17.4 | 42.5 | 31.1 |
| Corpus size | |||
| Texts per person | 1 | 344.92 | 1 |
| Words per person | 55.13 | 19847.89 | 84.25 |
| CCR loadings | |||
| CCR, M (SD) | 0.82 (0.02) | 0.77 (0.03) | 0.83 (0.02) |
| aCCR, M (SD) | 0.03 (0.08) | 0.02 (0.04) | 0.09 (0.03) |
Note. The cut-off for severe depression in the PHQ-9 was 20, while in the BDI-II the cut-off was set at a score of 30.
Results of Psychometric Evaluation
Face Validity
Figure 2 shows z-standardized CCR loadings for five example texts from dep_wor_data. Texts with higher CCR loadings described more acute/severe symptoms of depression, indicating that assessments based on CCRs exhibit face validity.
Content Validity
The semantic similarity among BDI-II items (within similarity; M = 0.797, SD = 0.035) was higher than the similarity of BDI-II items to DASS-42 anxiety and stress items (between similarity; M = 0.767, SD = 0.029, t = 11.25, p < .001, d = 0.99). Furthermore, BDI-II items were significantly more similar to DASS-42 depression items (M = 0.791, SD = 0.037) than to both DASS-42 anxiety (M = 0.758, SD = 0.028, t = 12, p < .001, d = 0.99) and stress items (M = 0.775, SD = 0.026, t = 5.78, p < .001, d = 0.48). See Figure 2
Symptom relevance ratings could be predicted above chance for all 21 BDI-II symptoms with a mean classification performance of AUROC = 0.68 (SD = 0.06, range = [0.57; 0.77], Figure 2, Table 6).
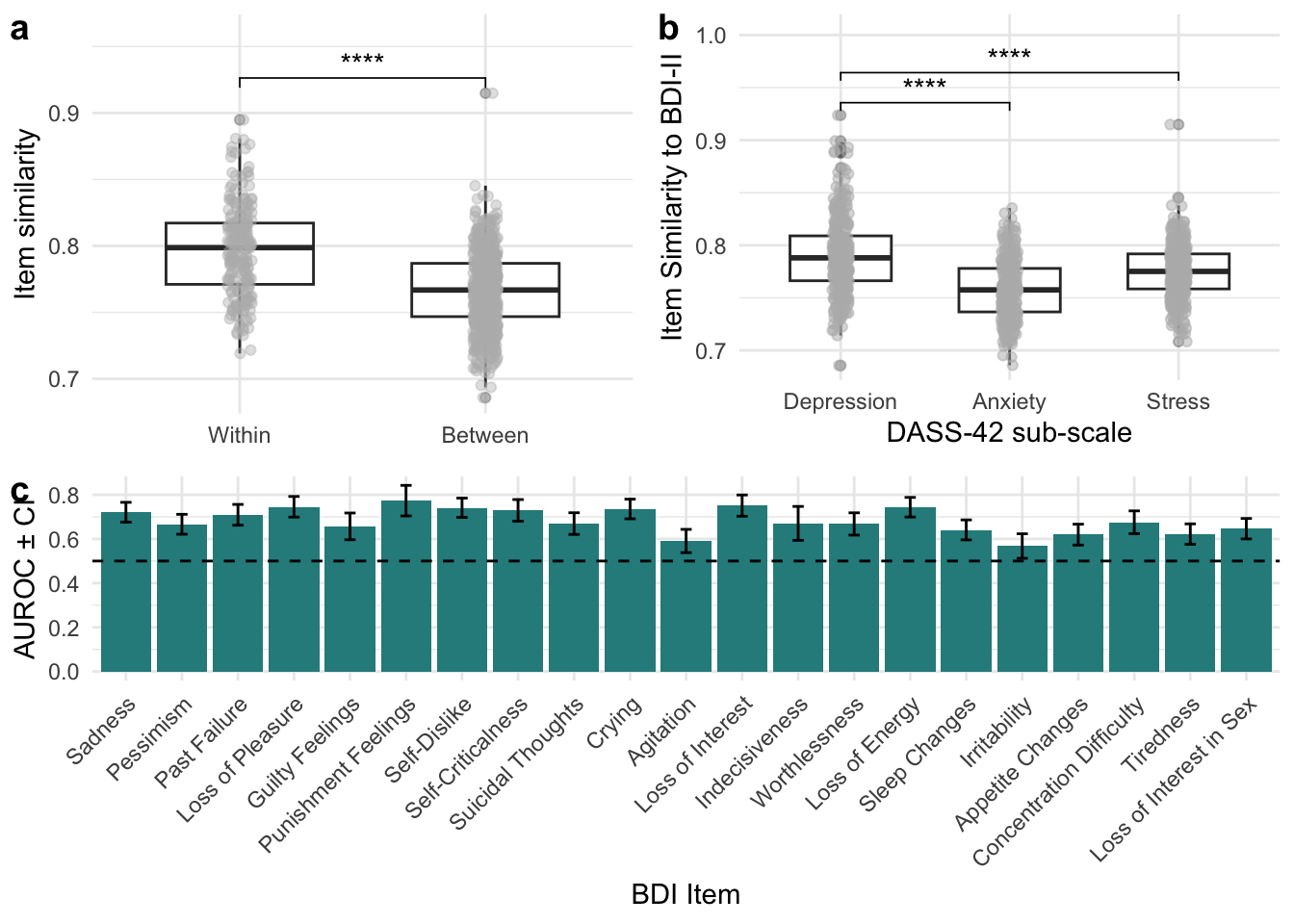
Note. a, Boxplots comparing the semantic similarity among BDI-II items (Within) with the similarity of BDI-II items to DASS-42 anxiety and stress items (Between). b, Boxplots comparing the semantic similarity of DASS-42 sub-scale items to BDI-II items. c, Barplot indicating the performance of a logistic regression classifier trained to predict BDI-item relevance ratings. For a given BDI-item, the semantic similarity of sentences to positive and negative item formulations served as input features. Significance was assessed based on the CI (error bars) of the area-under-the-receiver-operating-curve (AUROC). *p < .05,**p < .01, ***p < .001, ****p < .0001, ns = p > .05.
Convergent Validity
Significant positive correlations of language-assessed depression with self-reported depression scores emerged across all data-sets and methods (see Figure 3). Text-rating correlations were highest in dep_wor_data, with moderate correlations for CCR (r = 0.43, p < .001) and significantly larger correlations for aCCR (r = 0.64, p < .001), and yet larger correlations for RR (r = 0.69, p < .001), and PLS (r = 0.68, p < .001). In eRisk-2021, small-to-moderate correlations emerged for CCR (r = 0.31, p = .006), aCCR (r = 0.36, p = .001), and PLS (r = 0.26, p = .022), while RR (r = 0.15, p = .193) showed no significant correlation and was outperformed by aCCR and PLS. In META-FBZ, small correlations were found for CCR (r = 0.17, p < .001), aCCR (r = 0.14, p < .001), RR (r = 0.26, p < .001), and PLS (r = 0.26, p < .001) with RR outperforming aCCR and PLS outperforming both CCR and aCCR. Full results of text-rating correlation comparisons are given in Table 3.
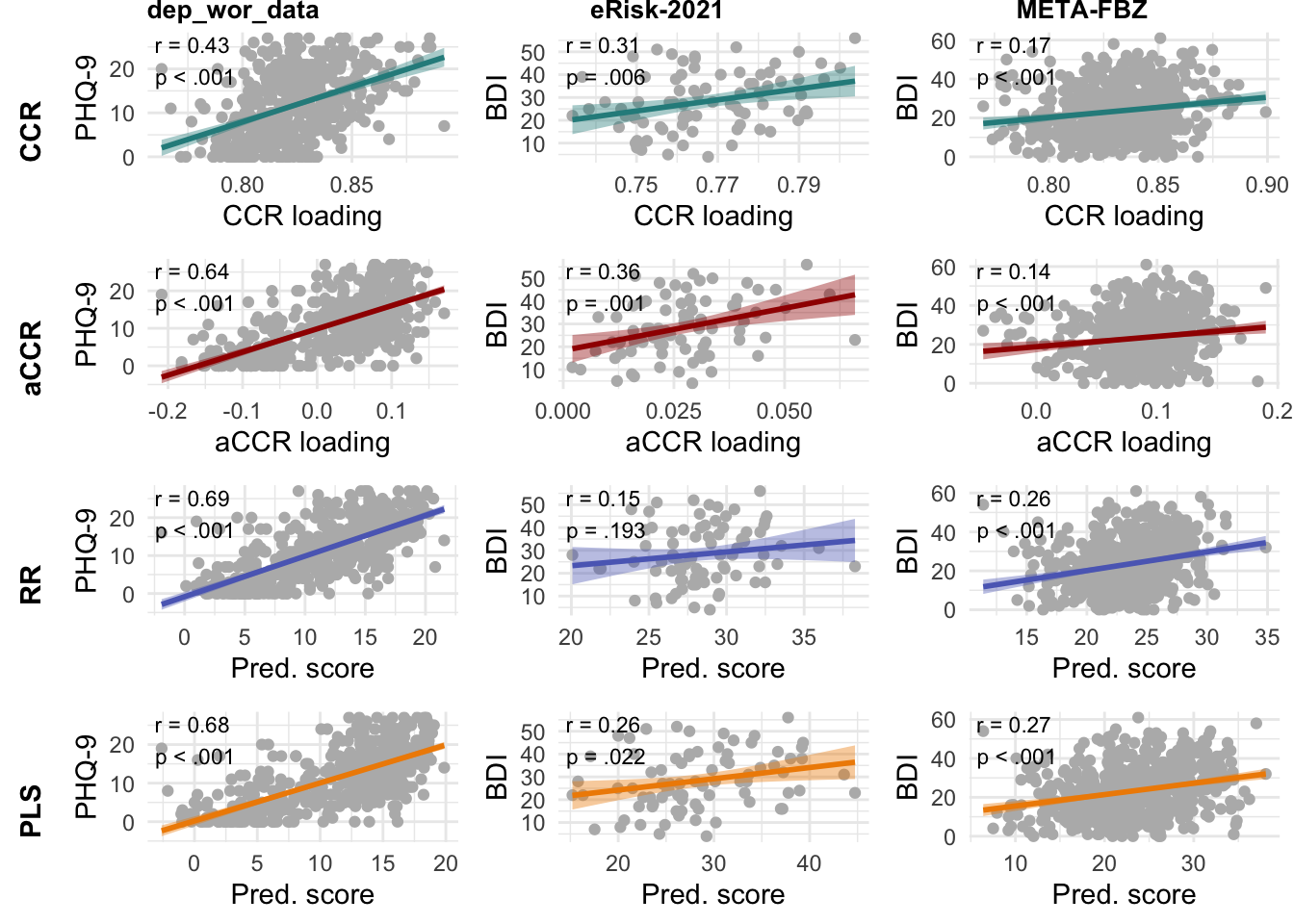
Note. Correlations of language-assessed depression with self-reported depression. Rows show correlations for CCR, aCCR, RR, and PLS, columns show correlations for data-sets dep_wor_data, eRisk-2021, and META-FBZ.
| Method 1 | Method 2 | r M1 | r M2 | r M1,M2 | z | p |
|---|---|---|---|---|---|---|
| dep_wor_data | ||||||
| CCR | aCCR | 0.43 | 0.64 | 0.57 | -6.09 | p < .001 |
| CCR | RR | 0.43 | 0.69 | 0.57 | -8.19 | p < .001 |
| CCR | PLS | 0.43 | 0.68 | 0.57 | -7.67 | p < .001 |
| aCCR | RR | 0.64 | 0.69 | 0.87 | -3.53 | p < .001 |
| aCCR | PLS | 0.64 | 0.68 | 0.95 | -4.2 | p < .001 |
| RR | PLS | 0.69 | 0.68 | 0.94 | 1.32 | p = .188 |
| eRisk-2021 | ||||||
| CCR | aCCR | 0.31 | 0.36 | 0.66 | -0.61 | p = .542 |
| CCR | RR | 0.31 | 0.15 | 0.64 | 1.71 | p = .088 |
| CCR | PLS | 0.31 | 0.26 | 0.69 | 0.59 | p = .557 |
| aCCR | RR | 0.36 | 0.15 | 0.66 | 2.37 | p = .018 |
| aCCR | PLS | 0.36 | 0.26 | 0.72 | 1.29 | p = .197 |
| RR | PLS | 0.15 | 0.26 | 0.95 | -3.06 | p = .002 |
| META-FBZ | ||||||
| CCR | aCCR | 0.17 | 0.14 | 0.37 | 0.71 | p = .475 |
| CCR | RR | 0.17 | 0.26 | 0.38 | -1.94 | p = .053 |
| CCR | PLS | 0.17 | 0.27 | 0.44 | -2.3 | p = .022 |
| aCCR | RR | 0.14 | 0.26 | 0.26 | -2.44 | p = .015 |
| aCCR | PLS | 0.14 | 0.27 | 0.25 | -2.64 | p = .008 |
| RR | PLS | 0.26 | 0.27 | 0.92 | -0.72 | p = .471 |
Note. Comparison of text-rating correlations between LBA methods using Steiger tests.
Results of transfer performance tests indicated that supervised LBA can generalize to novel domains, although not consistently and with significant losses in performance (see Figure 4 for visualization). Models trained on dep_wor_data showed the greatest transfer performance with significant text-rating correlations on both eRisk-2021 (RR: r = 0.37, p < .001; PLS: r = 0.39, p < .001) and META-FBZ (RR: r = 0.19, p < .001; PLS: r = 0.14, p < .001). Models trained on eRisk-2021 showed poorer generalization performance with decreased text-rating correlation on dep_wor_data (RR: r = 0.44, p < .001; PLS: r = 0.42, p < .001) and non-significant correlations on META-FBZ (RR: r = 0.07, p = .088; PLS: r = 0.07, p = .098). Models trained META-FBZ showed inconsistent results with losses in performance on dep_wor_data (RR: r = 0.34, p < .001; PLS: r = 0.31, p < .001) and no significant correlations on eRisk-2021 (RR: r = 0.2, p = .072; PLS: r = 0.22, p = .050). Table 7 contrasts text-rating correlations of transfer models with those involving CCRs. Transfer models trained on dep_wor_data performed as well on unseen test data as aCCR and CCR. In contrast, when transfer models were trained on either eRisk-2021 or META-FBZ, significant performance losses emerged.
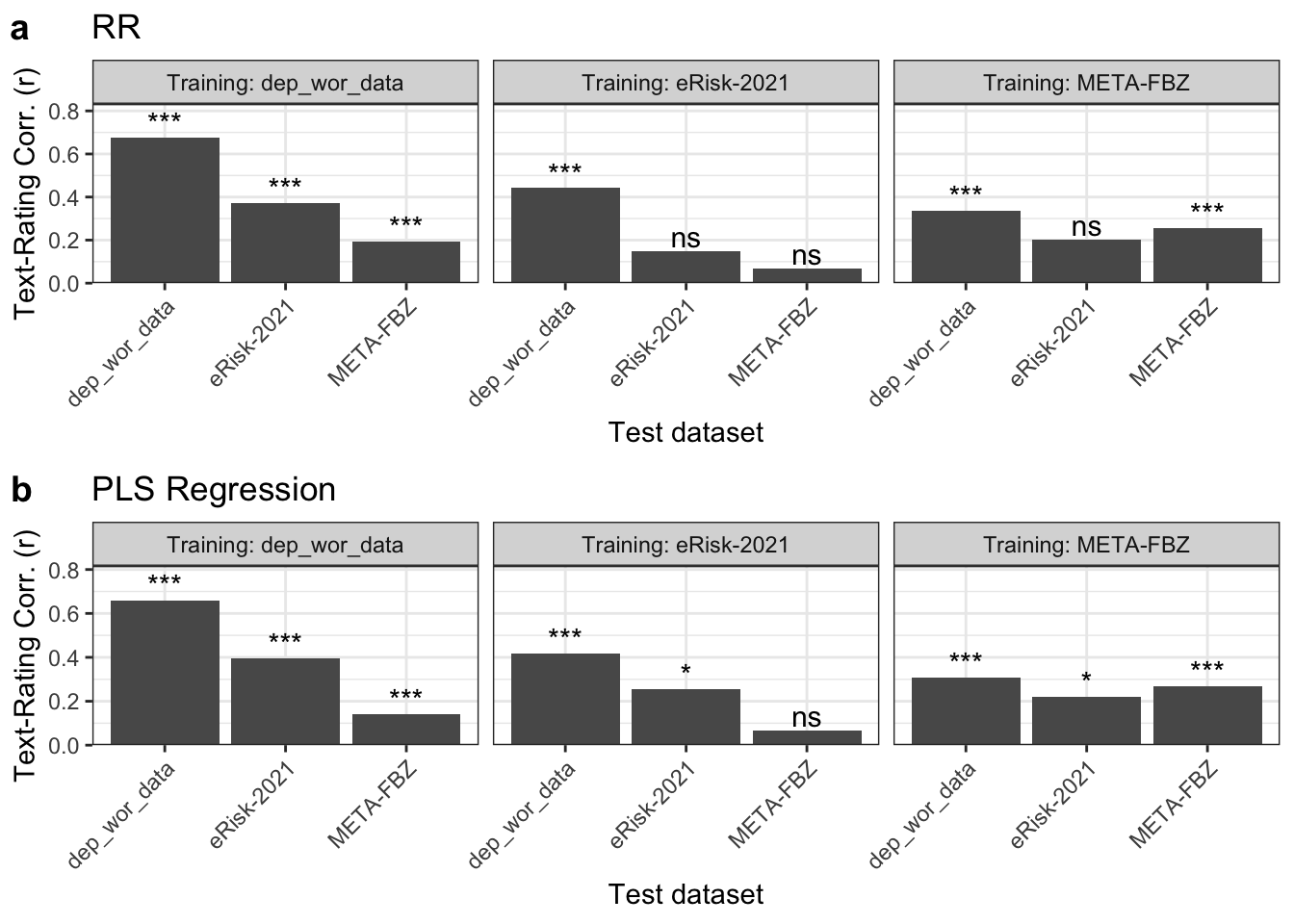
Note. Transfer performance of LBA based on RR (a) and PLS (b) measured as text-rating correlations for LBA models trained in one data-set and tested in another. *p < .05,**p < .01, ***p < .001, ****p < .0001, ns = p > .05.
Divergent Validity
In META-FBZ, all LBA methods resulted in significant positive correlations with DASS-42 Depression scores (CCR: r = 0.16, p = .001; aCCR: r = 0.11, p = .022; RR: r = 0.19, p < .001; PLS: r = 0.23, p < .001). In contrast, text-rating correlations with DASS-42 Anxiety were significant only for CCR (r = 0.1, p = .034). Correlations with DASS-42 stress were significant only for RR (r = 0.12, p = .017) and PLS (r = 0.12, p = .017). When comparing text-rating correlation strength, only RR and PLS significantly differentiated depression from anxiety, and only PLS significantly differentiated depression from stress.
In dep_wor_data, all LAB methods resulted in significant positive correlations with GAD-7 scores (CCR: r = 0.39, p < .001; aCCR: r = 0.59, p < .001; RR: r = 0.63, p < .001; PLS: r = 0.62, p < .001). Comparing text-rating correlations, all methods were able to significantly differentiate depression from anxiety.
| Method | N | r A | r B | r A,B | z | p |
|---|---|---|---|---|---|---|
| dep_wor_data | ||||||
| PHQ-9 vs GAD-7 | ||||||
| CCR | 500 | 0.43 | 0.39 | 0.83 | 2.02 | p = .044 |
| aCCR | 500 | 0.64 | 0.59 | 0.83 | 2.34 | p = .019 |
| RR | 500 | 0.69 | 0.63 | 0.83 | 3.39 | p < .001 |
| PLS | 500 | 0.68 | 0.62 | 0.83 | 3.02 | p = .003 |
| META-FBZ | ||||||
| DASS Depression vs DASS Anxiety | ||||||
| CCR | 411 | 0.16 | 0.1 | 0.5 | 1.15 | p = .249 |
| aCCR | 411 | 0.11 | 0.04 | 0.5 | 1.42 | p = .156 |
| RR | 411 | 0.19 | 0.03 | 0.5 | 3.26 | p = .001 |
| PLS | 411 | 0.23 | 0 | 0.5 | 4.63 | p < .001 |
| DASS Depression vs DASS Stress | ||||||
| CCR | 411 | 0.16 | 0.09 | 0.61 | 1.63 | p = .104 |
| aCCR | 411 | 0.11 | 0.07 | 0.61 | 0.96 | p = .336 |
| RR | 411 | 0.19 | 0.12 | 0.61 | 1.69 | p = .091 |
| PLS | 411 | 0.23 | 0.12 | 0.61 | 2.6 | p = .009 |
Note. Steiger tests were computed to compare text-rating correlations between different LBA methods.
Criterion Validity
In META-FBZ, language-assessed depression was elevated in outpatients with a primary depressive disorder for CCR (d = 0.41, p < .001), RR (d = 0.46, p < .001), PLS (d = 0.54, p < .001), but not aCCR (d = 0.12, p = .128). Language-assessed depression was not increased in outpatients who were on sick leave when compared to those who were able to work at the time of assessment. In dep_wor_data, language-assessed depression was significantly positively correlated with the number of healthcare visits for CCR (r = 0.14, p = .002), aCCR(r = 0.22, p < .001), RR (r = 0.23, p < .001), and PLS (r = 0.22, p < .001). Likewise, language-assessed depression was significantly positively correlated with the number of sick leave days for CCR (r = 0.12, p = .007), aCCR(r = 0.16, p < .001), RR (r = 0.19, p < .001), and PLS (r = 0.18, p < .001). See Figure 5 and Table 5.
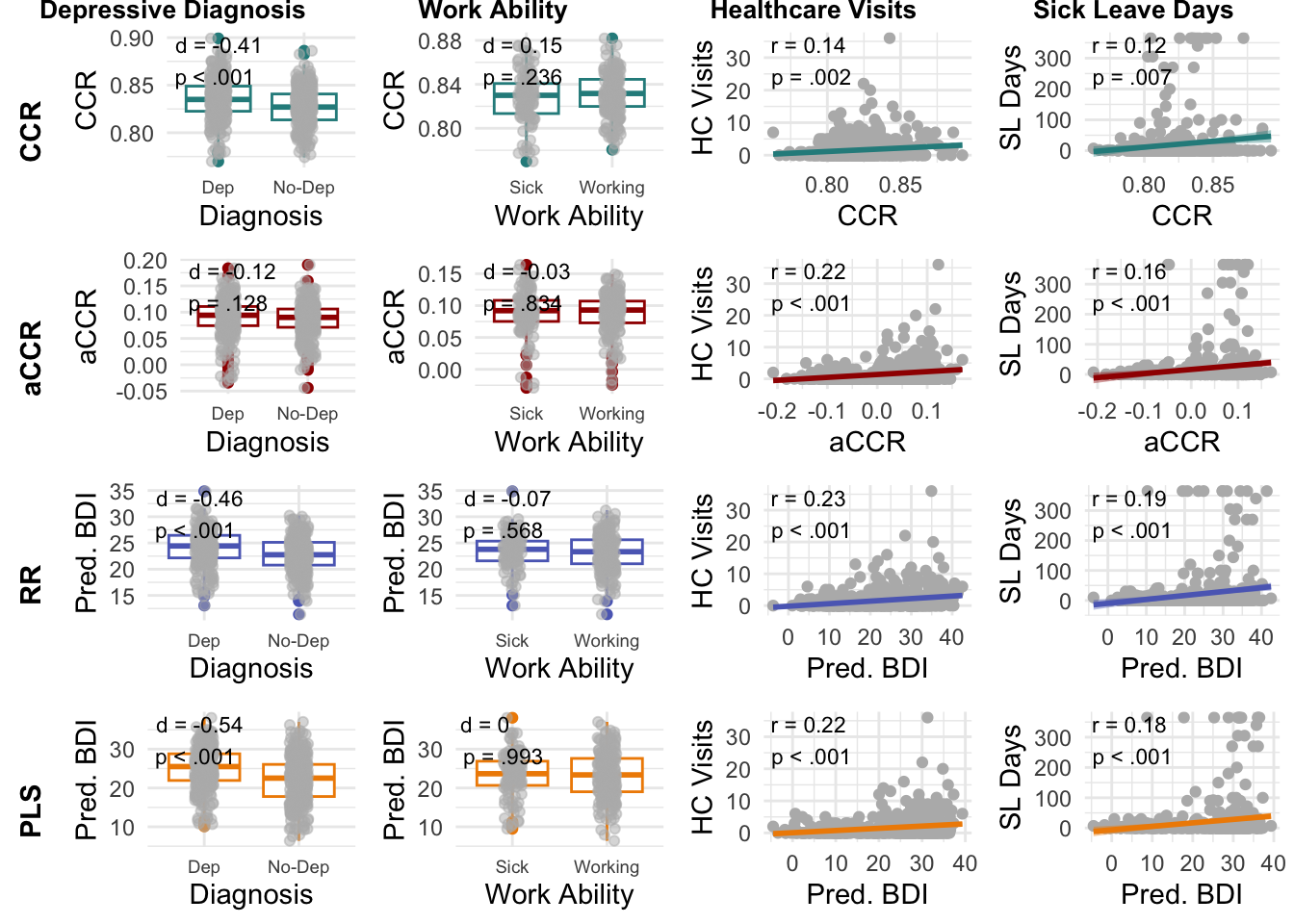
Note. Associations of language-assessed depression based on CCR (first row), aCCR (second row), RR (third row), and PLS (fourth row) with the presence of gold-standard depression diagnosis (first column, META-FBZ), current work ability status (second column, META-FBZ), HC Visits = healthcare visits in the past year (third column, dep_wor_data), and SL Days = sick leave days in the past year (fourth column, dep_wor_data).
| Method | Effect Size | t | p |
|---|---|---|---|
| META-FBZ (N = 601) | |||
| Primary Depression Diagnosis | |||
| CCR | d = 0.41 | t = 5.04 | p < .001 |
| aCCR | d = 0.12 | t = 1.52 | p = .128 |
| RR | d = 0.46 | t = 5.62 | p < .001 |
| PLS | d = 0.54 | t = 6.61 | p < .001 |
| Work Ability Status | |||
| CCR | d = -0.15 | t = -1.19 | p = .236 |
| aCCR | d = 0.03 | t = 0.21 | p = .834 |
| RR | d = 0.07 | t = 0.57 | p = .568 |
| PLS | d = 0 | t = -0.01 | p = .993 |
| dep_wor_data (N = 500) | |||
| Healthcare Visits | |||
| CCR | r = 0.14 | t = 3.05 | p = .002 |
| aCCR | r = 0.22 | t = 5.05 | p < .001 |
| RR | r = 0.23 | t = 5.36 | p < .001 |
| PLS | r = 0.22 | t = 4.94 | p < .001 |
| Sick Leave Days | |||
| CCR | r = 0.12 | t = 2.73 | p = .007 |
| aCCR | r = 0.16 | t = 3.68 | p < .001 |
| RR | r = 0.19 | t = 4.39 | p < .001 |
| PLS | r = 0.18 | t = 4.1 | p < .001 |
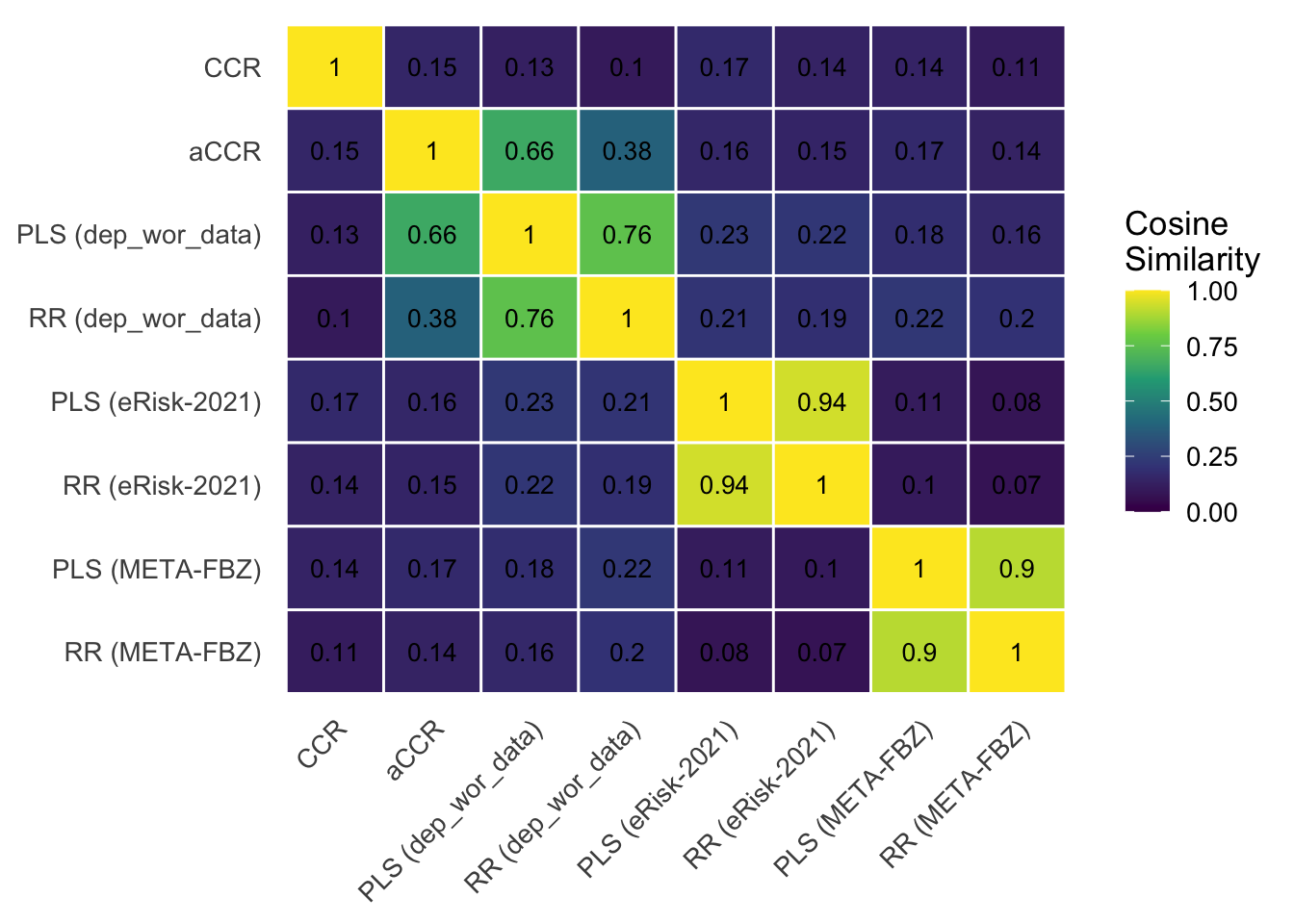
Similarity of Learned and Theory-Driven Vectors
Supervised LBA and theory-defined vectors yielded comparable text-rating correlations. We were therefore interested in whether vector directions learned during supervised training would be similar to theory-defined directions. To this end, we computed the cosine similarity of all vector pairs (see Figure 6). This analysis revealed that learned vector representations are generally quite dissimilar (0.07 - 0.23), except when RR and PLS models are trained on the same data-set (0.76 - 0.94). CCRs and aCCRs also were dissimilar from both each other (0.15) and from RR/PLS vectors (0.1 - 0.17). A crucial exception was found in dep_wor_data, with a similarity of aCCR and PLS (0.66) that is comparable to the similarity of PLS and RR (0.76). This means that PLS trained on texts targeting depressive symptoms converges on a vector representation that is similar, although not identical, to the semantic representation of the BDI-II.
Discussion
The goal of the present study was to evaluate the psychometric qualities of CCRs, with a focus on domain-generality, for the assessment of depression symptoms. When compared to state-of-the-art LBA, CCRs demonstrated high validity and good performance across various domains and are thus supported as domain-general, interpretable, and highly valid tools for the assessment of depression from language. Interestingly, findings also revealed that supervised LBA, which has previously been hypothesized to generalize poorly across strongly diverging domains (Nilsson et al., 2026; Teitelbaum & Simchon, 2025), achieves strong domain-generality under certain training regimes. Moreover, supervised LBA converged on a vector representation that is similar to the semantic representation of the BDI-II. Thus, in addition to validating the use of CCRs, our findings lend further support for the validity of supervised LBA. In the following, we will discuss these findings in detail and provide recommendations about when to use which LBA method.
Both CCR types yielded significant text-rating correlations that were comparable in magnitude to supervised LBA. In dep_wor_data, performance losses (relative to aCCR) were minimal (), in eRisk-2021 non-significant, and in META-FBZ more notable (). When trained on social media data, RR was unable to generate significant text-rating correlations, underlining the sensitivity of supervised LBA to small samples and noisy data. PLS did achieve significant text-rating correlations under these conditions which supports recent suggestions to use PLS for LBA (Teitelbaum & Simchon, 2025). However, to arrive at definitive conclusions regarding meaningful differences between PLS and RR, more research on different constructs is certainly needed.
Results of the transfer tests speak directly to the measurement-versus-prediction question raised in the introduction. When supervised LBA models were trained on outpatient anamnesis texts (META-FBZ) or social-media texts (eRisk-2021), notable performance losses occurred under transfer. Such losses admit two non-exclusive interpretations. A model may have learned domain-specific correlates of depression alongside construct-central features; alternatively, or in addition, the linguistic expression of depression may genuinely differ across these domains, such that a representation learned in one register transfers imperfectly to another even when both validly index the construct. Transfer performance alone does not adjudicate between these readings, which is why we complement it with content-validity and representational analyses. When trained on language probes specifically targeting depressive symptomatology (dep_wor_data), however, no performance loss was detectable. Critically, the vector similarity analysis disambiguates this finding: the PLS model trained on construct-targeted language converged on a vector representation substantially similar to the theory-defined aCCR (cosine similarity = .66, approaching the within-method similarity of RR and PLS). It is the conjunction of these two results — domain-general performance and convergence of the learned representation on the questionnaire-defined construct representation — that allows the interpretation that this model approximates measurement of the depression construct rather than prediction from correlated signals. Taken together, these findings suggest that LBA methods are best located on a continuum between prediction and reflective measurement, and that a model’s position on this continuum is determined not by the use of language per se, but by whether the indicator-construct mapping is theoretically specified (CCR), learned from construct-targeted elicitation (supervised LBA on probes), or learned from naturalistic corpora (supervised LBA on found text).
The context-dependence of construct expression also helps account for the gradient observed for CCR, whose convergent validity decreased from construct-targeted symptom descriptions (dep_wor_data, r = .43) through spontaneous social-media posts (eRisk-2021, r = .31) to clinical intake narratives (META-FBZ, r = .17). Because CCR fixes its construct representation in the linguistic register of questionnaire items, its loadings should be highest where elicited language most closely approximates that register — as when participants are asked to describe their symptoms directly — and lower where language is produced for other communicative purposes, such as recounting the development of one’s difficulties at clinical intake. On this view, the gradient reflects, at least in part, the varying distance between domain-typical language and the questionnaire register rather than a uniform loss of construct validity. The same logic offers a constructive reading of why supervised LBA generalized best when trained on construct-targeted elicitation: such elicitation draws spontaneous language toward the canonical expression of the construct, narrowing the register gap that transfer must bridge. Both methods, then, appear to track the depression construct; they differ in how their performance is modulated by the linguistic register of the domain in which the construct is expressed.
Tests of divergent validity revealed an ability of LBA to differentiate between depression and related constructs, although results were not entirely affirmative. In dep_wor_data, where text-rating correlations were generally high, all methods significantly differentiated between depression and generalized anxiety. In META-FBZ, where text-rating correlations were small, results were less consistent. aCCR correlated significantly with depression but not significantly with anxiety or stress, although differences between these correlations were not significant. Supervised LBAs did show significant correlations with stress, although these correlations were significantly smaller than correlations with depression. The lesser discriminant validity of CCRs in META-FBZ could stem from the small magnitude of correlations, as CCRs demonstrated substantial discriminant validity in dep_wor_data where correlations were moderate to large in size.
LBAs were significantly associated with three out of four external criteria, namely gold-standard depression diagnoses, as well as the number of healthcare visits and sick leave days. No difference in language-assessed depression was found for mental health outpatients who were currently working vs. on sick leave at the time of assessment. Additionally, only CCR- but not aCCR loadings were elevated in outpatients with a depression diagnosis. In sum, these results support the criterion validity of LBA, but point towards some remaining inconsistencies.
Limitations and Future Work
While these results are promising, several limitations should be noted. Firstly, the presented analysis was confined to the assessment of depression symptoms, limiting extrapolation of findings to other psychological constructs. Indeed, prior work has shown that, for some dimensions of moral concerns, CCRs do not correlate significantly with questionnaire scores, potentially implying that some psychological constructs are not well represented in natural language (Teitelbaum & Simchon, 2025). Secondly, our validation strategy shares a construct definition with its criterion: CCRs are constructed from BDI-II items and evaluated, in part, against BDI-II and PHQ-9 scores. Convergent validity coefficients therefore reflect agreement between two operationalizations derived from the same nomological tradition rather than agreement with the construct itself — a limitation that applies to all validation of new instruments against established self-reports (Cronbach & Meehl, 1955). The criterion validity findings (clinical diagnoses, healthcare utilization) partially mitigate this concern, as these criteria are external to the self-report operationalization. Future work should expand the criterion space toward method-independent indicators (e.g., clinician ratings, behavioral measures, longitudinal treatment outcomes) to probe whether language-based scores carry construct-relevant information beyond the questionnaire-defined operationalization. Relatedly, our domain comparisons confound data domain with elicitation format and linguistic register. We therefore cannot fully separate genuine context-dependence in the expression of depression from register-related method effects. Future designs could hold register constant across domains, or vary it systematically within a domain, to disentangle these influences and to test directly whether the construct’s linguistic manifestation is itself domain-variable. Thirdly, the comparatively small number of individuals included in the eRisk-2021 data-sets possibly led to under-powered correlation comparisons. Fourthly, we considered here supervised LBA as a comparison method, but note that the use of zero-shot prompting has yielded impressive results for LBA of personality (Wright et al., 2026) and mental health (J.-J. Lee et al., 2026). This choice was motivated by the fact that supervised LBA represents the current state-of-the-art and has been validated extensively, therefore serving as the critical comparison benchmark. Still, it would be desirable for future studies to undertake a systematic comparisons of these three methods.
Choosing a method
The results of this study provide insight into the strengths and weaknesses of different LBA methods, raising the question what method to select in a given research scenario. We propose that method selection depends chiefly on two factors: the goal of the assessment and the available data.
When the goal is prediction, e.g. screening for at-risk individuals or stratifying patients into treatment groups in a highly standardized setting where large amounts of gold-standard data can be accumulated, supervised LBA will most often be indicated. In such scenarios, it is legitimate and indeed desirable for a model to exploit all available predictive information, including semantic information that is predictive of, but not reflective of, the target construct: a screening instrument is evaluated by its predictive utility, not by the purity of its construct representation. Validity evidence remains necessary, but domain-generality does not take precedence over within-domain accuracy.
When the goal is measurement, that is, when scores are intended to be interpreted as reflecting standing on the depression construct, compared across populations or settings, or related to other constructs in theory testing, the requirements shift. Here, construct specificity and an explicit indicator-construct mapping become paramount, and CCR is the preferable choice: it offers an interpretable, a priori specified construct representation that is not conflated with correlated traits and that can be deployed in domains where gold-standard ground truth is unavailable (e.g., historical records; (Chen et al., 2024)). Transferring a supervised LBA trained on construct-targeted language elicitation is a viable alternative, as the present results show, but such models must be inspected carefully; ideally including a comparison of the learned representation against a theory-defined construct vector, as demonstrated here.
Supplementary Material
| BDI Item | N Relevant | N Irrelevant | AUROC | Lower CI | Upper CI |
|---|---|---|---|---|---|
| 1 | 167 | 414 | 0.72 | 0.68 | 0.77 |
| 2 | 209 | 343 | 0.67 | 0.62 | 0.71 |
| 3 | 146 | 390 | 0.71 | 0.66 | 0.76 |
| 4 | 132 | 390 | 0.75 | 0.70 | 0.79 |
| 5 | 88 | 312 | 0.66 | 0.60 | 0.72 |
| 6 | 33 | 519 | 0.77 | 0.70 | 0.84 |
| 7 | 205 | 269 | 0.74 | 0.70 | 0.78 |
| 8 | 115 | 419 | 0.73 | 0.68 | 0.78 |
| 9 | 300 | 217 | 0.67 | 0.62 | 0.72 |
| 10 | 143 | 403 | 0.74 | 0.69 | 0.78 |
| 11 | 142 | 451 | 0.59 | 0.54 | 0.64 |
| 12 | 105 | 448 | 0.75 | 0.70 | 0.80 |
| 13 | 50 | 534 | 0.67 | 0.59 | 0.75 |
| 14 | 161 | 263 | 0.67 | 0.62 | 0.72 |
| 15 | 161 | 330 | 0.74 | 0.70 | 0.79 |
| 16 | 274 | 294 | 0.64 | 0.60 | 0.69 |
| 17 | 132 | 408 | 0.57 | 0.51 | 0.62 |
| 18 | 225 | 323 | 0.62 | 0.57 | 0.67 |
| 19 | 166 | 262 | 0.68 | 0.62 | 0.73 |
| 20 | 217 | 349 | 0.62 | 0.58 | 0.67 |
| 21 | 239 | 291 | 0.65 | 0.60 | 0.69 |
Note. Results of logistic regressions predicting symptom relevance labels based on positive and negative BDI-II item centroids.
| Sample | CCR | Transfer Model | r(CCR, BDI) | r(Pred, BDI) | r(CCR, Pred) | n | z | p |
|---|---|---|---|---|---|---|---|---|
| eRisk-2021 | CCR | RR (dep_wor_data) | 0.306 | 0.374 | 0.669 | 80 | -0.787 | = 0.431 |
| eRisk-2021 | aCCR | RR (dep_wor_data) | 0.360 | 0.374 | 0.863 | 80 | -0.257 | = 0.797 |
| eRisk-2021 | CCR | PLS (dep_wor_data) | 0.306 | 0.394 | 0.624 | 80 | -0.964 | = 0.335 |
| eRisk-2021 | aCCR | PLS (dep_wor_data) | 0.360 | 0.394 | 0.901 | 80 | -0.735 | = 0.462 |
| eRisk-2021 | CCR | RR (META-FBZ) | 0.306 | 0.202 | 0.640 | 80 | 1.118 | = 0.264 |
| eRisk-2021 | aCCR | RR (META-FBZ) | 0.360 | 0.202 | 0.478 | 80 | 1.430 | = 0.153 |
| eRisk-2021 | CCR | PLS (META-FBZ) | 0.306 | 0.220 | 0.641 | 80 | 0.927 | = 0.354 |
| eRisk-2021 | aCCR | PLS (META-FBZ) | 0.360 | 0.220 | 0.498 | 80 | 1.293 | = 0.196 |
| dep_wor_data | CCR | RR (eRisk) | 0.430 | 0.441 | 0.418 | 500 | -0.268 | = 0.789 |
| dep_wor_data | aCCR | RR (eRisk) | 0.618 | 0.441 | 0.510 | 500 | 4.965 | < .001 |
| dep_wor_data | CCR | PLS (eRisk) | 0.430 | 0.416 | 0.317 | 500 | 0.303 | = 0.762 |
| dep_wor_data | aCCR | PLS (eRisk) | 0.618 | 0.416 | 0.442 | 500 | 5.298 | < .001 |
| dep_wor_data | CCR | RR (META-FBZ) | 0.430 | 0.338 | 0.445 | 500 | 2.168 | = 0.030 |
| dep_wor_data | aCCR | RR (META-FBZ) | 0.618 | 0.338 | 0.338 | 500 | 6.619 | < .001 |
| dep_wor_data | CCR | PLS (META-FBZ) | 0.430 | 0.306 | 0.429 | 500 | 2.859 | = 0.004 |
| dep_wor_data | aCCR | PLS (META-FBZ) | 0.618 | 0.306 | 0.325 | 500 | 7.237 | < .001 |
| META-FBZ | CCR | RR (eRisk-2021) | 0.170 | 0.070 | 0.270 | 601 | 2.050 | = 0.040 |
| META-FBZ | aCCR | RR (eRisk-2021) | 0.138 | 0.070 | 0.129 | 601 | 1.269 | = 0.204 |
| META-FBZ | CCR | PLS (eRisk-2021) | 0.170 | 0.068 | 0.240 | 601 | 2.052 | = 0.040 |
| META-FBZ | aCCR | PLS (eRisk-2021) | 0.138 | 0.068 | 0.129 | 601 | 1.309 | = 0.191 |
| META-FBZ | CCR | RR (dep_wor_data) | 0.170 | 0.191 | 0.266 | 601 | -0.441 | = 0.659 |
| META-FBZ | aCCR | RR (dep_wor_data) | 0.138 | 0.191 | 0.525 | 601 | -1.369 | = 0.171 |
| META-FBZ | CCR | PLS (dep_wor_data) | 0.170 | 0.142 | 0.289 | 601 | 0.572 | = 0.568 |
| META-FBZ | aCCR | PLS (dep_wor_data) | 0.138 | 0.142 | 0.763 | 601 | -0.174 | = 0.862 |
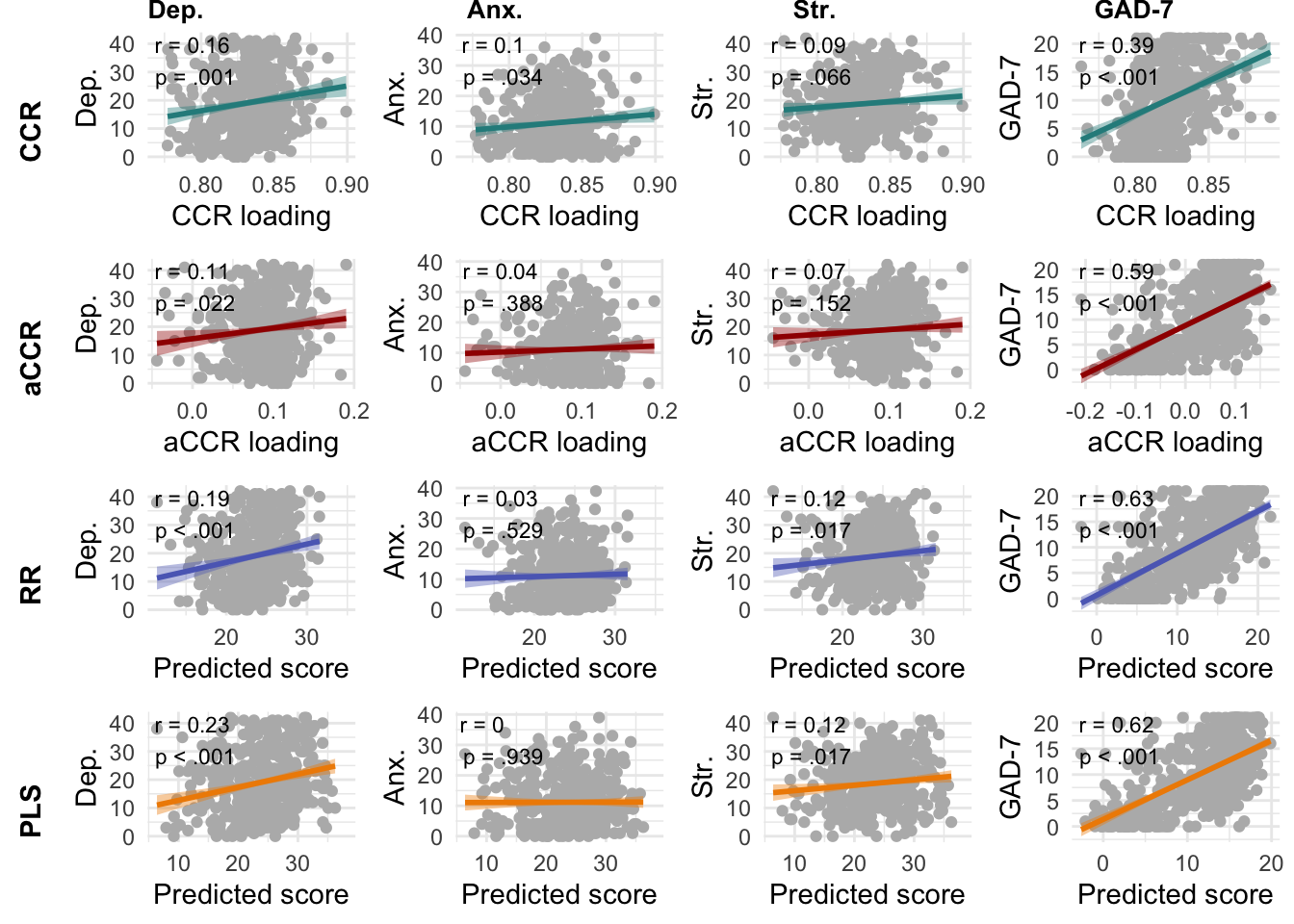
Note. Pearson correlations of language-assessed depression based on CCR (first row), aCCR (second row), RR (third row), and PLS (fourth row) with self-reports of DASS-21 depression (Dep., first column, META-FBZ), DASS-21 anxiety (Anx., second column, META-FBZ), DASS-21 stress (Str., third column, META-FBZ), and GAD-7 anxiety (fourth column, dep_wor_data).
References
Footnotes
available at https://huggingface.co/openai/whisper-large-v2↩︎
Model available at https://huggingface.co/flair/ner-german-large↩︎
Available at https://github.com/cran/topics/blob/master/data/dep_wor_data.rda↩︎
Researchers may apply for access at https://erisk.irlab.org/↩︎
Available at https://huggingface.co/mixedbread-ai/deepset-mxbai-embed-de-large-v1↩︎
Available at https://huggingface.co/intfloat/multilingual-e5-large↩︎